



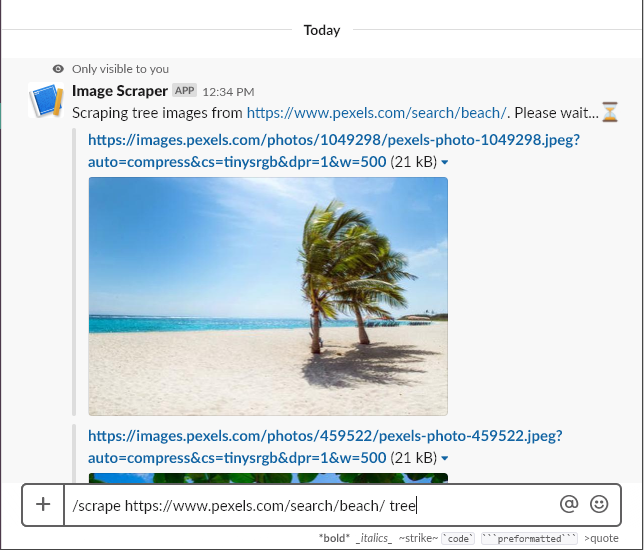
This post will detail the steps to get a serverless slack command running on AWS Lambda using the Jets Serverless Ruby framework. We’ll make something fun: a command that takes in a URL, scrapes all the images on the page, filters the images using AWS image recognition, and posts the filtered images to the current slack channel. For example:
Create a Slack app
- Go to api.slack.com/apps and click Create an App.

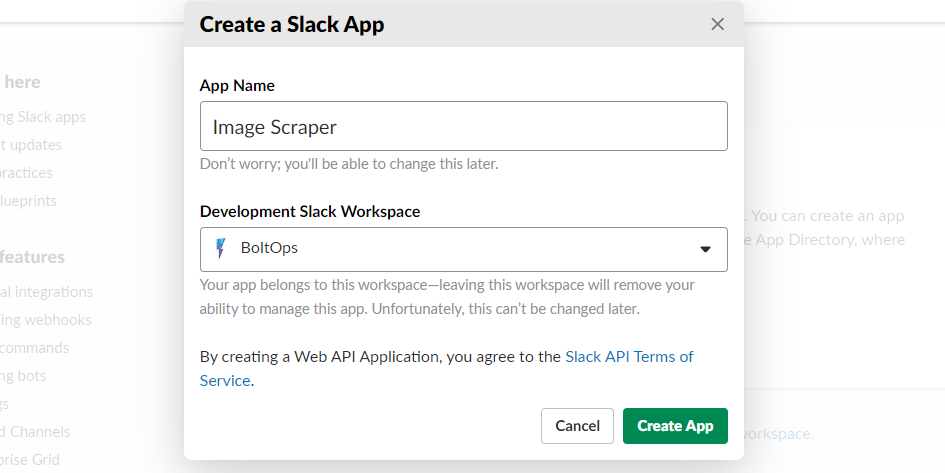
- Name the app “Image Scraper”, select your workspace from the dropdown, and click on “Create App”.
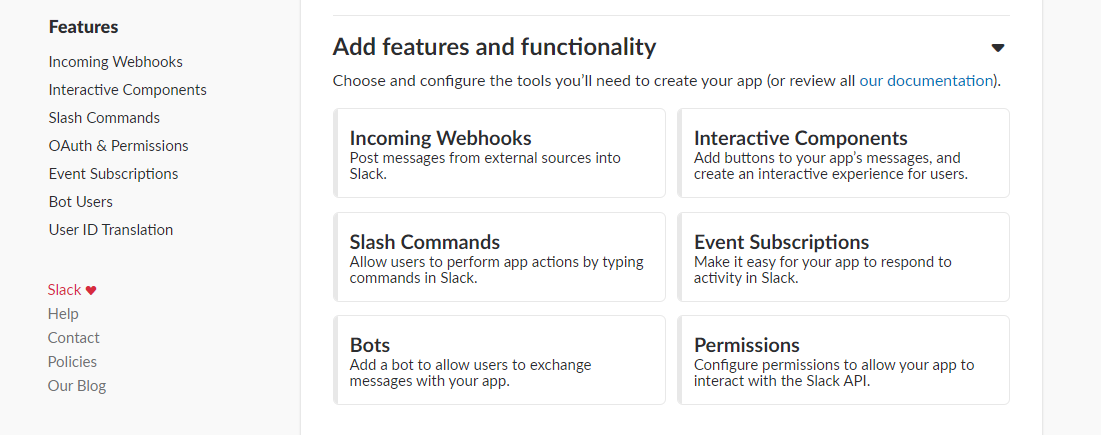
- Expand “Add features and Functionality”, and click on “Slash Commands”.
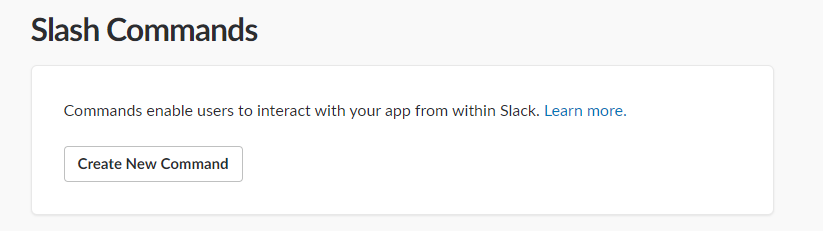
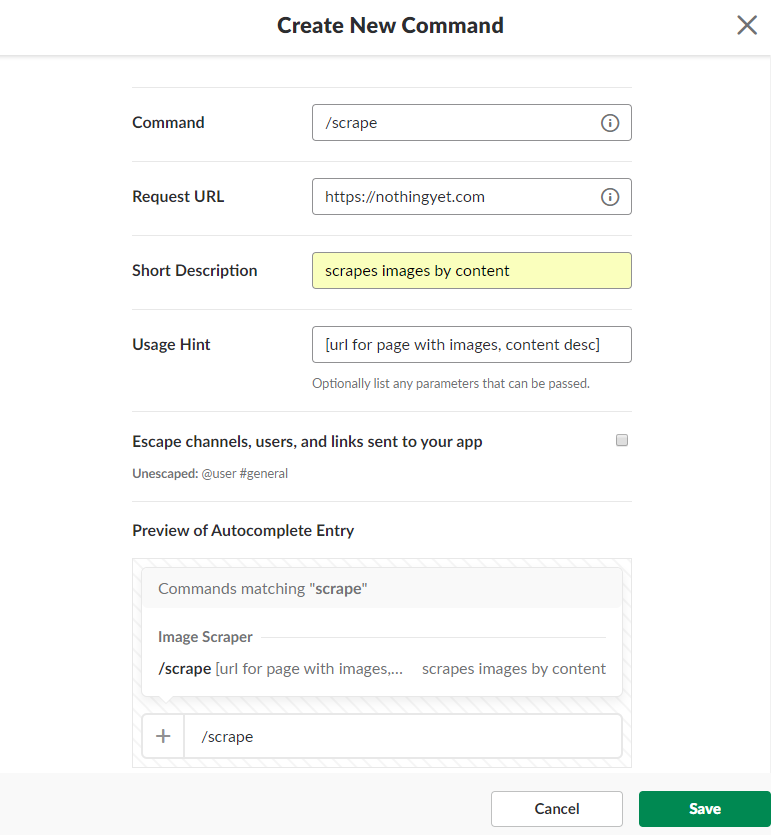
- Click on “Create New Command”
- Enter the information as in the image bellow and click on the “Save” button. We will return to this page and fill in the “Request URL” field with a real endpoint after we’ve deployed our Lambda function.
- Click on “install App” on the side menu, and click on the “install App to Workspace” button.
Create a Jets project
- Install Jets and create the project
gem install jets
jets new slack_image_scraper --mode=api
- Add Nokogiri and Typhoeus to your Gemfile
source "https://rubygems.org"
gem "jets"
gem "nokogiri"
gem "typhoeus"
- Install your gems
bundle install
Create and deploy the API endpoint
- Create a new route for
scrapein routes.rb that maps toscrape_images#scrape
Jets.application.routes.draw do
root "jets/public#show"
post "scrape", to: "scrape_images#scrape"
any "\*catchall", to: "jets/public#show"
end
- Install gems
bundle install
- Create
app/controllers/scrape_images_controller.rband add an action namedscrape
class ScrapeImagesController < ApplicationController
def scrape
render json: { # immediate response to slack
response_type: 'ephemeral',
text: "You've deployed a Slack command!"
}
end
end
- Deploy the endpoint
jets deploy
Once the deploy completes, the terminal will give you the base url for your deployed Jets app.
- Go back to https://api.slack.com/apps, click on your app, and click on “Slash Commands” on the side bar.
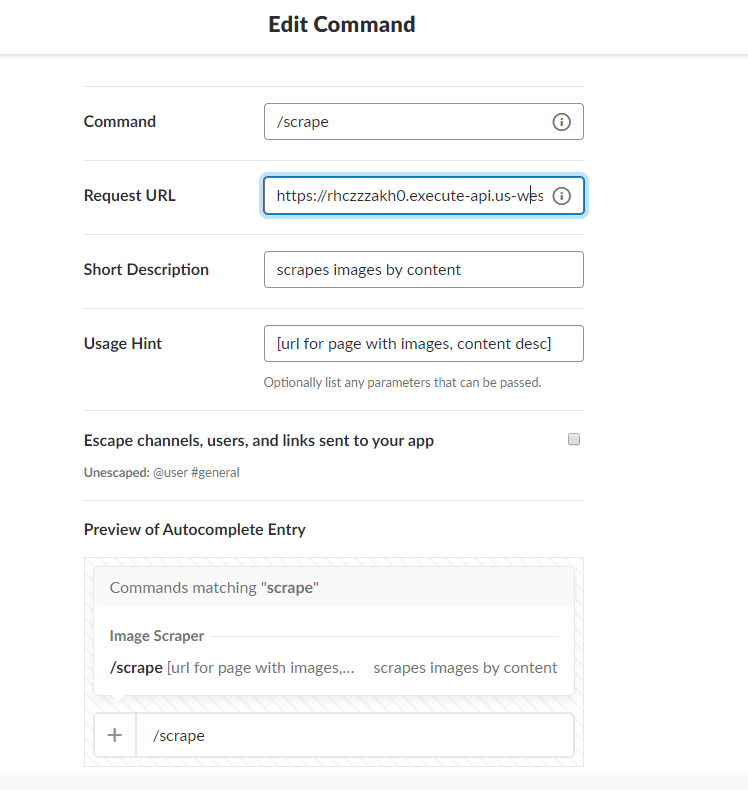
- Click on the edit button, and enter the base url + “/scrape” into the “Request URL” field. Click Save.
At this point, we’ve gotten the boilerplate out of the way and have a working Slack command. You can see it in action by typing /scrape into slack.
Our command doesn’t do anything interesting yet, so let’s have some fun with it. Let’s make it scrape the images from a web page that contain a subject of our choosing. We’ll pass the page URL and image subject in as parameters. The command will look as follows:
/scrape https://www.pexel.com/search/beach tree
This will scrape all images in that page which contain trees. Once we’ve scraped the images, we’ll post them back to the Slack channel. You can get the code for the project here.
Having fun with AWS Rekognition
With AWS Rekognition, you can get a list of subjects contained in an image with a couple commands. In ruby, all we have to do is the following:
rekognition = Aws::Rekognition::Client.new
labels = rekognition.detect_labels({image: {bytes: <image bytes>})
That’s it! You can read more about Rekognition here. The full ruby documentation is here.
Lets create a class named FilteredImageSet which uses Rekognition to filter images as they’re pushed into the set. We’ll put it in app/models/filtered_image_set.rb. Here’s the code:
class FilteredImageSet < Set
attr_reader :subject_filter
def initialize(collection = [], subject_filter: "cat")
@subject_filter = subject_filter
@rekognition = Aws::Rekognition::Client.new
super(collection)
end
def <<(image)
begin
super if subject_detected_in?(image)
rescue # notify error tracker
end
image
end
private
def subject_detected_in?(image)
response = @rekognition.detect_labels({
image: {
bytes: image.bytes
}
})
labels = response.labels.map { |label| label.name.downcase }
matches = [@subject_filter, @subject_filter.singularize] & labels
matches.present?
end
end
As you can see on when items are pushed to the set using the << operator, they will only be added if they contain the subject we’re looking for.
Creating an AWS Lambda background job with Jets
Our process for analyzing images is slow because we’re downloading the images from a web page and then uploading them to Rekognition. It would be faster to analyze the images if we stored them in an S3 bucket and passed S3 object references to Rekognition, but let’s just move the work to a background job so that this howto doesn’t get too complicated. Create a file named app/jobs/scrape_and_filter_images_job.rb. Here’s the code:
class ScrapeAndFilterImagesJob < ApplicationJob
iam_policy("rekognition") # needed to use FilteredImageSet
def run
desired_image_subject = event["desired_image_subject"]
image_page_url = event["image_page_url"]
slack_response_url = event["slack_response_url"]
desired_images = FilteredImageSet.new(subject_filter: desired_image_subject)
download_images(from: image_page_url, into: desired_images)
post_images_to_slack(from: desired_images, to: slack_response_url)
end
private
def download_images(from:, into:, limit: 25)
image_page_url, desired_images = from, into
image_urls = image_urls_from(image_page_url)
hydra = Typhoeus::Hydra.new # for request threading
image_urls[0...limit].each do |url|
Typhoeus::Request.new(url).tap do |request|
request.on_complete do |response|
desired_images << OpenStruct.new({url: url, bytes: response.body})
end
hydra.queue(request)
end
end
hydra.run
end
def image_urls_from(image_page_url)
page_html = Typhoeus::Request.get(image_page_url).body
Nokogiri::HTML(page_html).css("img").map { |img| img["src"] }.compact.uniq
end
def post_images_to_slack(from:, to:)
desired_images, slack_response_url = from, to
post_body = if desired_images.present?
{
response_type: "ephemeral",
attachments: desired_images.map { |image|
{
title: image.url,
image_url: image.url
}
}
}
else
{
response_type: "ephemeral",
text: "No #{desired_images.subject_filter.singularize} images found... :disappointed:"
}
end
Typhoeus.post(slack_response_url, body: post_body.to_json)
end
end
This background job will itself be an AWS Lambda function, and as you can see, we’ve given it permission to access the AWS Rekognition service with the line iam_policy("rekognition"). The function will need to have access because it uses the FilteredImageSet class, which accesses Rekognition. You might wonder why we don’t give access to the FilteredImageSet class instead. The reason is that the background job gets converted to an AWS resource (an AWS Lamdba) when we deploy, whereas the FilteredImageSet class does not; it’s just code that gets executed by our Lambda function.
We can get a pretty clear idea of what’s happening by reading the run method in the background job. The job uses Nokogiri to extract image URLs from a web page, uses Typhoeus to download the images, filters the images with Rekognition, and then posts the results to the slack response URL. Whenever slack commands send requests to our endpoint, they include a special parameter named “response_url”. The purpose of the URL is precisely so we can take our time creating a response and then post it to slack asynchronously. The post payload may look unfamiliar if you’ve never worked with Slack commands before, but it’s pretty straightforward to understand once you’ve read a little bit of their documentation.
Invoking our background job
We have one thing left to do. Let’s handle the request made by the Slack command to our endpoint, and invoke our background job. Here’s the updated controller:
class ScrapeImagesController < ApplicationController
iam_policy("lambda") # needed to call background job lambda
def scrape
slack_response_url = params[:response_url]
image_page_url, desired_image_subject = parse_args(params[:text])
ScrapeAndFilterImagesJob.perform_later(:run, {
desired_image_subject: desired_image_subject,
image_page_url: image_page_url,
slack_response_url: slack_response_url
})
text <<~EOL
Scraping #{desired_image_subject.singularize} images from #{image_page_url}.
Please wait...:hourglass_flowing_sand:
EOL
render json: { # immediate response to slack
response_type: "ephemeral",
text: text
}
end
private
def parse_args(args_str)
tokens = args_str.split(" ").map(&:strip) # remove extra spaces
[tokens[0], tokens[1..-1].join(" ")]
end
end
Notice that we’ve responded to slack immediately after invoking our background job. We have to do this within 3 seconds of Slack sending the request, or we’ll cause a timeout. We’re just notifying the user that we’re in the process of creating the response that they want, which we’ll post to the “response_url” that Slack sent us with their request.
Making the code production-ready
This demo is not production-ready. Off the top of my head, we should:
- Authenticate the request to make sure it’s coming from slack.
- Add some rate-limiting so that we don’t analyze images beyond our budget.
- Optimize the image-analyzing process by downloading the images to S3, and then passing S3 object references to Rekognition instead of sending bytes.
That’s it for now. I hope you found this tutorial useful or at least fun. You can get the code here. Please add a star to the Jets project here to help us grow the community. Also, there’s a Discuss forum here that you might find helpful.